在前端工程化盛行的今天,很多公司为了提升开发效率与项目可维护性,都开始使用上了webpack这样的自动化工具。在享受自动化高效率的同时,也产生了一些性能上的问题:代码重复引用、臃肿的混合JS库、编译速度慢……,很多技术人员面对此类问题无从下手,求助于百度但是却不求甚解。所以本文将通过我工作中实际遇到的问题进行分析、解释原因、并给出解决方案的几个步骤,来讲解前端自动化中的优化问题。
本文章基于以下CC协议进行知识共享:署名(BY)-非商业性使用(NC)-禁止演绎(ND)
注意:
- 本文假设您已有webpack基础,并了解基本的配置项的意义。适用于在此基础上希望能了解一些 webpack 的优化规则的情况。
- 本文不会详细到具体的实施代码,仅提供思路,具体操作请查阅webpack文档。
问题1:编译后文件体积过大
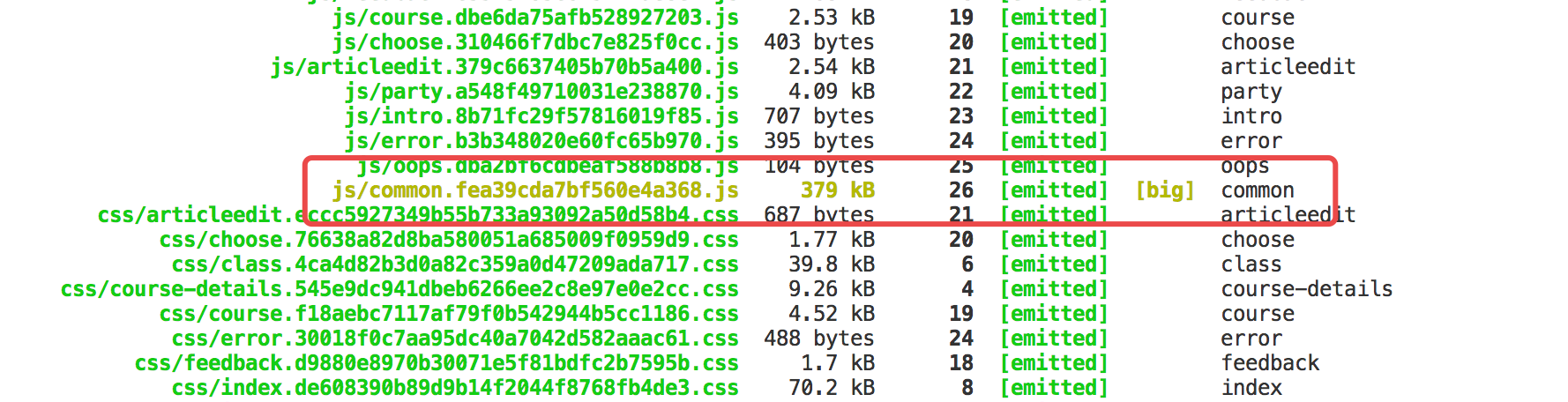
该问题是指执行编译后,webpack在控制台输出的数据中的资源体积过大。一般会用黄色的字体标注上[big]。有时编译策略的错误,会导致代码文件达到5、6MB甚至10MB以上。假设用户的网速是2MB/s,加载一次页面也需要3s,并且再考虑到服务器的出口带宽,可能就需要数十秒才能显示出页面。
但是,文件体积过大又分很多种情况,所以要具体情况具体分析。我们先从最简单的开始说。
CSS文件过大
一般CSS文件不会过大,而且也没什么可优化的,毕竟CSS只是描述样式,没有逻辑,所以不会像JS出现重复引用的问题。只需要确保 LoaderOptionsPlugin 下开启了 minimize 。打包后的CSS就会自动去除不必要的换行符和空格等。
JS文件过大
JS 文件过大的情况处理起来就比较复杂了,因为有很多可能性会导致JS文件过大。为了不盲目的解决问题,我们需要使用 webpack-bundle-analyzer 这个工具来分析具体是什么原因导致的问题。
重复引用
重复引用是一个非常常见的问题,虽然很多 webpack 脚手架都自带了 CommonsChunkPlugin 的配置 —— 将重复引用的JS模块打包进一个总的混合JS包中(常见命名:Common.js / Vendor.js / Lib.js……),这样做的好处是降低页面加载时的并发量。参见:加载缓慢/HTTP并发
但是偶尔的,在某些特定情况下 CommonsChunkPlugin 会没起到作用。我们使用 webpack-bundle-analyzer 分析一下编译后的代码引用结构。
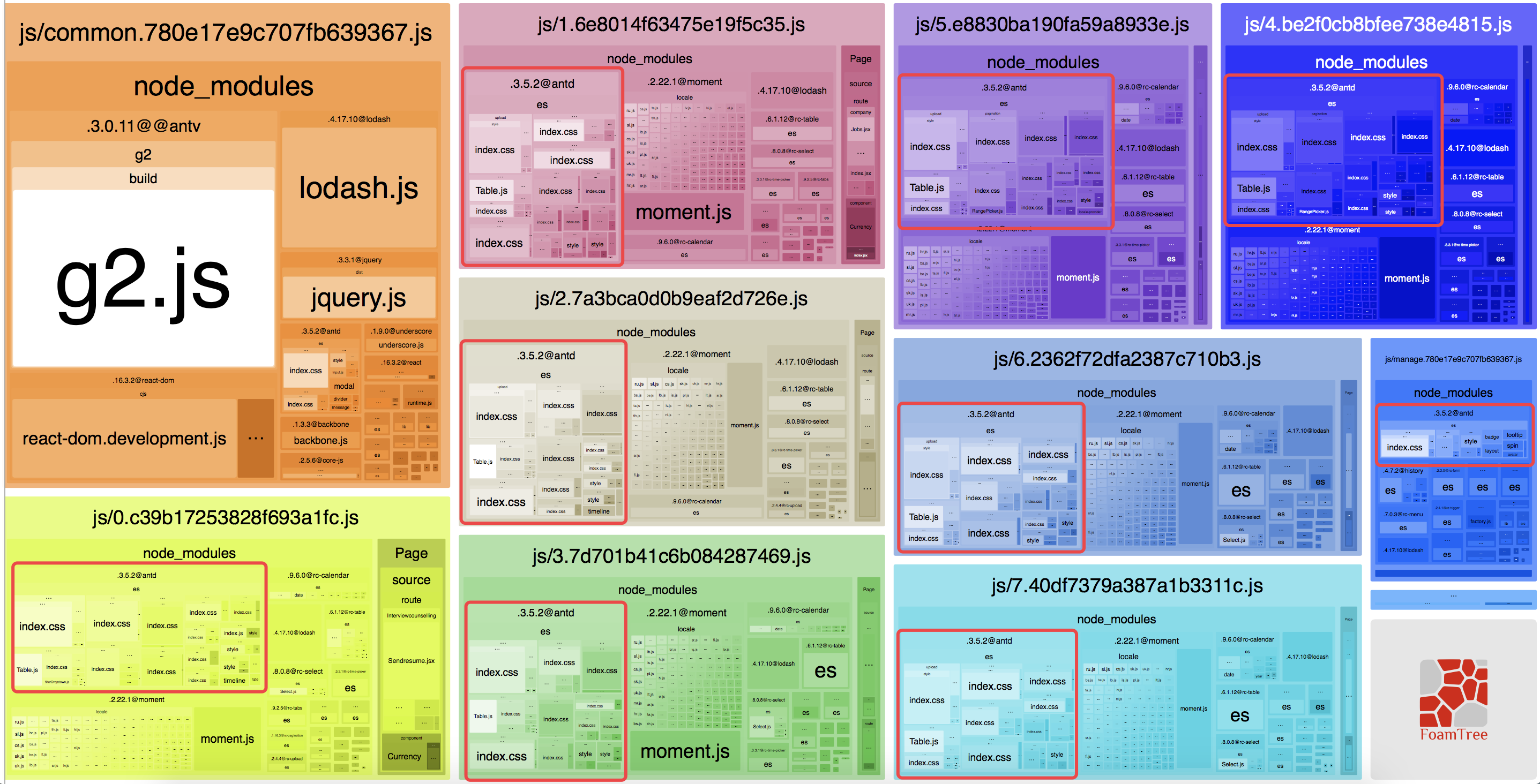
仔细观察上图,我们就会发现所有被按需加载的页面,都反复加载了 Ant.Design 组件库中使用到的组件。假如每个页面都用到了 Button 组件,那么当用户浏览网页中的其他内容时, Button 组件将会反复的被加载,白白浪费了网络带宽。
这个问题是因为项目按照 Ant.Design 官方文档的配置,增加了组件库的按需加载。因此使整个组件库独立出 CommonsChunkPlugin 的策略外了。
所以针对这个特殊情况,我们其实应该将 Ant.Design 从代码中抽离出来,然后使用 CDN 加载。虽然一次性的加载了一个非常大的类库,但是进入缓存后,后面的加载就会非常快了。同时,由于是后台系统,基本上一个页面中能用到的组件都用到了,使用按需加载会反复加载N次很多相同的组件代码。两者相比较起来,按需加载实际上就没有意义了。
第三方类库
第三方类库一般是引起 Vendor.js 这样的文件过大的主要原因,实际上除非特殊需要,我们没有必要将第三方类库打包进我们的项目中。一般都是通过一些第三方的CDN服务(如:BootCDN)来引入类库,1是能减少网站自身的流量使用,2是用户访问过其他网站,并且那个网站使用了同一个CDN地址时,就会直接命中缓存,而不用重新加载,减少了用户的等待时间。
webpack版本过低
这个问题目前(2018-05-17)应该不会有了,毕竟都已经webpack 4了。这里主要是想提一句 webpack 2 时增加的 Tree Shaking 代码优化技术。在一些公司的面试中可能会有考核,更多的内容,自己百度一下把。
按需加载
参见:加载缓慢/按需加载
问题2:加载缓慢
加载缓慢是指用户用户访问网站后长时间无法显示主要内容和页面。当我们通过问题1尽可能的缩减文件体积后,如果加载依然缓慢,就要考虑从服务器方面进行优化了。
加载请求并发
假设我们一个页面引用了 10 余个JS模块,当加载这些JS文件时,HTTP协议会进行3次握手4次挥手,相当于加载完整个页面,就与服务器进行了70余次的连接/断开通信,大部分时间就都浪费在了建立连接的网络通信上。因此我们使用 CommonsChunkPlugin 将各个页面都会用到的模块打包进一个综合的Vendor.js中。来降低多次建立连接与并发。
启用缓存
通过上面的步骤尽可能的优化代码体积后,下一步要做的就是开启缓存。如果不开启缓存的话,用户每一次打开网站,都会从服务器重复的加载相同的资源文件。这样显然也是白白浪费带宽了。
但是开启缓存后,如果我们更新了网站代码,浏览器会由于缓存原因,无法立刻同步最新代码。因此,我们需要使用 webpack 的 hash 标签来为资源文件进行命名。这样每一次编译的时候,资源文件都会被命名为类似 xxxx.fea39cda7bxxxx.js ,并且当文件内容发生变化后,hash 值也会发生变化,这样就会导致浏览器重新加载这个文件。也就达到了更新版本的目的了。
但是别忘了不要给html加缓存,否则HTML上的JS引用地址由于缓存也会无法更新了。以Nginx为例的配置:
1 | location ~ html$ { |
按需加载
按需加载实际上是一个与业务逻辑相关的优化方案,比如对于SPA应用,使用前端路由进行页面跳转,用按需加载进行优化就很合理了。通常会以页面为单位,进行代码分隔,然后访问到哪个路由时再单独加载。这样将不需要一次性加载完的代码分隔出去,就可以有效的减少单个的代码文件的体积。
按需加载的实现请参考 webpack 文档:require.ensure
问题3:编译缓慢
编译缓慢是指webpack在开发环境和生产环境,代码热更新慢、编译速度慢等问题。
使用 CommonsChunkPlugin 整合第三方类库
关于这个插件前面已经讲过很多了,这里主要说一下为什么使用 CommonsChunkPlugin 可以提升编译速度。主要是因为如果不整合第三方类库,每一次编译webpack都会重新处理页面中模块的引用关系,而特别大的类库也会重新加载编译。通过启用 CommonsChunkPlugin 将类库代码整合后再配合 DllPlugin & DllReferencePlugin 就可以极大的提高编译效率。
使用 DllPlugin & DllReferencePlugin 对第三方类库进行预编译
一般情况下我们会将第三方类库抽离出去,并通过 CDN 加载。但是如果是我们自己开发的类库、或者没有服务商托管该第三方类库的 CDN 链接的情况下,就只能编译进 Vendor.js 中。通常情况下类库是基本不会有代码变动的,但是 webpack 每次编译依然会重新处理这些类库,这样就导致重复做了很多工作,编译效率自然就低了。通过 DllPlugin & DllReferencePlugin 允许我们将不常变动的大类库预先处理,然后在需要的时候直接引用预编译的结果。一般情况下该方法能带来10~20s的速度提升。
开发环境下关闭不必要的Plugins
在开发环境时可以关闭uglifyjs-webpack-plugin、extract-text-webpack-plugin等插件。因为在开发环境下调试,没有必要对JS进行压缩或对CSS进行提取,同时这些插件会非常影响编译效率。但是有一点要注意的是,关闭extract-text-webpack-plugin后,开发环境下的页面的CSS将由JS进行填充,因此会导致页面刷新时有几百毫秒的样式丢失。同时类似Vue的v-clock也将失效。要注意区分,不要误以为是BUG。
另外 hash 也是一个影响编译效率的东西,因为需要计算文件的哈希值。
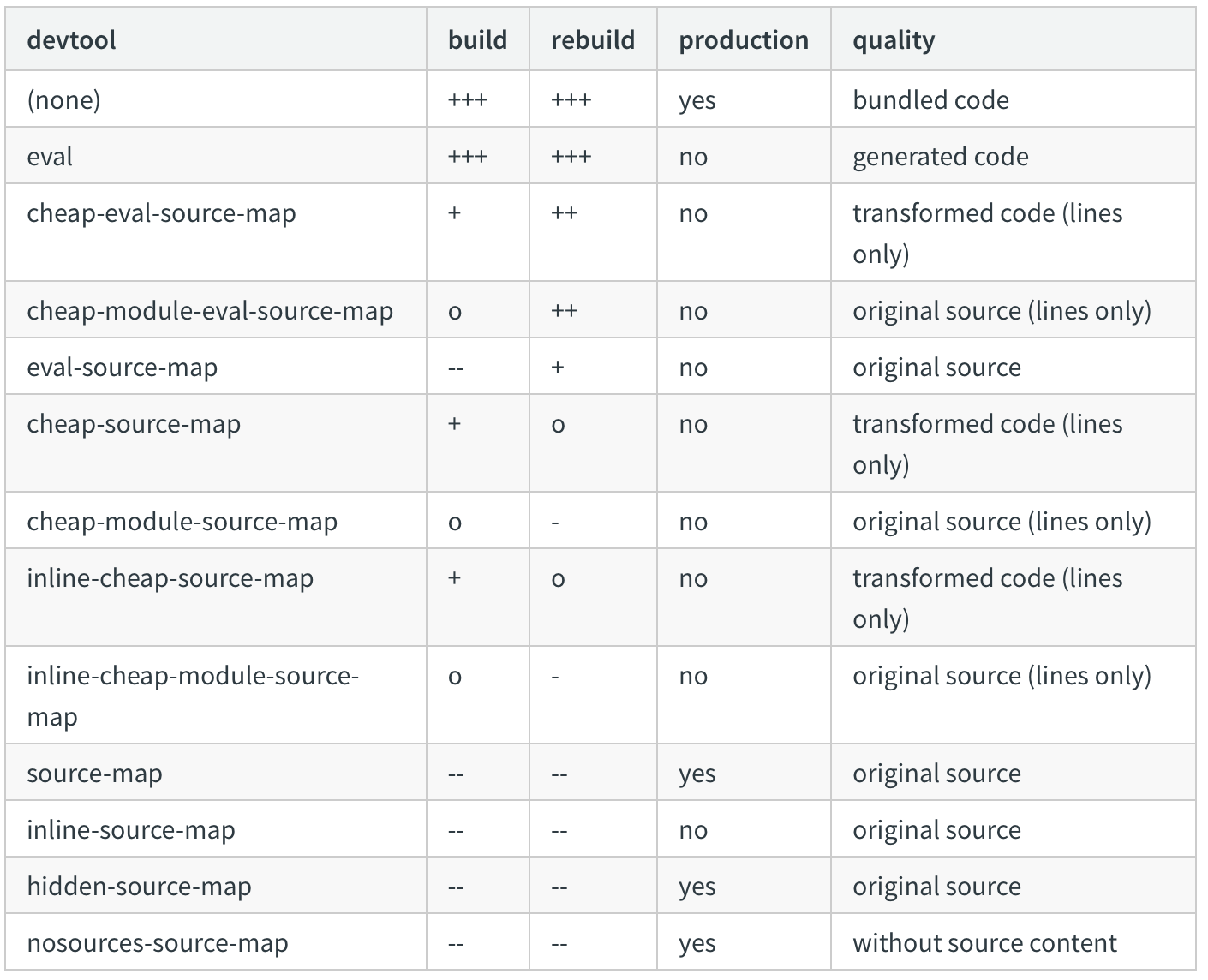
关闭 source-map 源映射
source-map 是一个能让开发者工具在编译后的代码中迅速找到对应的源代码的位置的功能,可以很方便的追踪到控制台的报错。但是,源映射本身非常影响编译效率,而在生产环境中,我们其实没有必要在线上追踪调试错误。毕竟你不能每时每刻的都在用户旁边盯着控制台报错然后点进去。最终我们都是从用户那里收集反馈,然后在开发环境下重现BUG。因此,生产环境的source-map是没必要开启的。
当然,如果你特别强烈的想在生产环境开启 source-map,那么可以参考一下webpack文档中source-map的几种方式,然后综合考虑一下(速度、功能)选择一个最适合你的方案。
使用 HappyPack 多线程编译
这个不必多说,由于webpack是跑在NodeJS下的,而NodeJS又是单线程,无法充分利用多核CPU的优势。使用 HappyPack 就可以解决这个问题,从而提升编译效率。具体实施请自行查看文档。
使用内存编译
webpack Node API 在编译时可以提供一个基于fs模块接口的文件系统,相比于直接对硬盘读写,使用 memory-fs 在内存中进行读写效率会高很多。